Table of Contents
A variety of tools are provided to assist in managing a BigWorld server. Broadly, these fall into three categories:
-
WebConsole
-
Cluster Control (See ClusterControl.)
-
Watchers (See Watchers.)
-
Log Viewer (See LogViewer.)
-
Space Viewer (See Space Viewer.)
-
Stat Grapher (See StatGrapher.)
-
Python Console (See Python Console.)
-
Commands (See Commands.)
-
-
Logging facilities
-
Message Logger (See Message Logger.)
-
Stat Logger (See StatLogger.)
-
-
Server command-line utilities (e.g., control_cluster.py) (See Server Command-Line Utilities.)
The server tools are implemented almost entirely in Python, and can be easily extended, if additional functionality is desired.
Most of the server tools' functionality is available from WebConsole, an easy to use web interface which simplifies server administration for remote users and non-programmers (e.g., artists, game designers, etc.) that may need to run and administer servers.
Almost all server tool functionality is also available via command-line utilities, which is useful when only system console access is available (e.g., when remotely administering a server cluster via ssh).
Where possible, documentation for the server tools is maintained as online help. For WebConsole, this means the Help link displayed in the navigation menu for each module. For command-line utilities, help is available via the --help switch.
This chapter provides an overview of the suite of tools available. For detailed documentation, however, please refer to the online help.
Located under bigworld/tools/server/web_console ,
WebConsole provides a simple web interface to manage and monitor a
BigWorld server. For details on how to install and run WebConsole, see the
document Server Installation Guide.
WebConsole is functionally divided into units referred to as Modules. Each module in WebConsole has a separate top level menu item in the main navigation menu on the left hand side of the page.
Complete documentation for each WebConsole module is provided as online help, accessible as a link on the left hand side of the WebConsole page.
WebConsole is composed of the modules described below.
-
Allows users to start, stop, and restart the game server.
-
Browse the active machines and users on the local network.
-
View and modify saved cluster configurations.
-
Allows users to view and modify Watcher values of active server processes.
-
Generate pre-configured and user generated tabular reports of watcher values across sets of server processes in a cluster.
-
Define custom sets of watcher values for live monitoring.
-
Allows users to view, filter, and search server message logs.
-
Provides a real time / live view of server output.
-
Summaries of per-user log usage.
Note
This tool is a HTML5 Canvas-based replacement for the existing "Space Viewer" tool detailed later in this Chapter (see Space Viewer).
-
Provides a summary overview of spaces and space information for a running server.
-
Provides a detailed, real-time visualisation of the cells, partitions and entities of a space in world coordinates.
-
Allows visualisation of additional space-related information including: cellapp IP address, cell/partition load balancing, partition aggression, loaded chunks, and entity bound levels.
For further information, refer to the documentation linked from within the Space Viewer online tool running in Web Console.
-
Allows users to connect to the Python server of any Python enabled process (i.e., CellApp, BaseApp, Bots).
For detailed instructions on installing and configuring WebConsole please refer to the Server Installation Guide.
The first time WebConsole is started you will need to add at least
one user in order to operate a BigWorld server. To achieve this, from
the front page of WebConsole, login with a username / password of
admin. If you have never loaded the WebConsole
homepage before, it should be visible at the url
http://hostname:8080,
where hostname is the network name of the
machine you install WebConsole on.

Once logged in you should be presented with a webpage similar to the following.
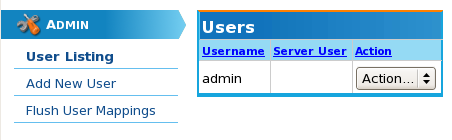
To add a new user, click on the "Add New User" menu item on the left hand side of the page. You will then be presented with a form to input as follows:
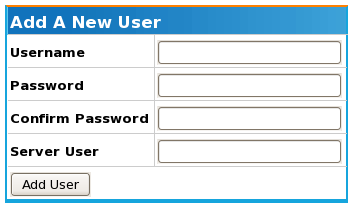
The table below summarises the input fields providing sample input:
| Field | Description |
|---|---|
| Username | The username that for the new user. |
| Password | The password with which the new user will log in. |
| Confirm Password | The password from the previous field, retyped to ensure no mistake was made on entry. |
| Server User |
The Linux user this account will be associated with. This will be the Linux user that the BigWorld server processes will be run as. If you are uncertain of this field, please talk to your system administrator to find out what your Linux user account is. |
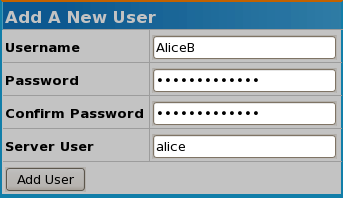
The following image shows a new user account AliceB being created and associated with the Linux user account alice:
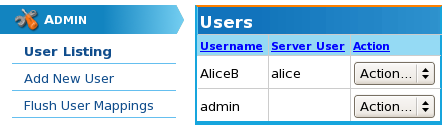
Once all the user information has been entered, simply click the button and you will be returned to the main user listing, which will include the new user:
The Flush User Mappings menu option provides the ability for WebConsole to force all BWMachined instances in the network to forget their current cached user list. This feature is useful and sometimes necessary when adding users to a network information system such as LDAP which are sometimes used as account management systems.
If you are having problems detecting a newly added user in your network, or are seeing an old user appear in your cluster display, flushing the user mapping will quite often help resolve the issue.
WebConsole can be started using two methods, as a system wide service or from the command line.
Generally, only developers working on modifying the web page
templates or underlying code will run WebConsole from the command line.
In order to achieve this, make sure that the current directory is
bigworld/tools/server/web_console, then
issue the command:
$ ./start-web_console.py
There are some minor operational differences when running WebConsole in command line mode vs as a system service:
-
When run as a system daemon, WebConsole uses the configuration file
prod.cfg, which defines a production environment mode. -
When run from the command line, WebConsole uses a development environment configuration file called
dev.cfg.
Running in development mode leaves the web server in a state where an automatic restart is triggered if there are any changes to the template files or Python code it is using.
The production configuration file does not exist by default in
bigworld/tools/server/web_console, as it is
partially generated during the installation process while using the
install_tools.py script. The original production
configuration file that the installation script uses is
bigworld/tools/server/install/web_console.cfg.
Both configuration files need to specify the database to use. Before running WebConsole, make sure that the appropriate configuration file has a line that looks like this:
sqlobject.dburi="notrans_mysql://username:password@localhost:3306/bw_web_console"
Specifying the database
To modify the
bigworld/tools/server/install/web_console.cfg file
to a working configuration file, replace the line:
###BW_SQLURI###
with an sqlobject.dburi line as indicated above.
For information regarding TurboGears configuration files and content, we recommend the TurboGears documentation website http://docs.turbogears.org/1.0/Configuration.
If you have never run WebConsole before and choose to run it from
the command line (as opposed to installing the system service), it is
necessary to create a database for WebConsole within MySQL. To do this,
connect to your MySQL database using the username and password that you
have defined in dev.cfg, then issue the following
command:
CREATE DATABASE bw_web_console;
As WebConsole is a convenient interface to your cluster environment, it may be useful to add new content to WebConsole that is unique to your companies requirements. To achieve this please refer to the Server Programming Guide chapter Web Console.
Message Logger is a process used for logging output from BigWorld
processes within a network. This is primarily intended as a mechanism for
logging output from server processes, however in a development environment
it can be useful for game clients and other tools to send log messages as
well. The source code for Message Logger can be located in bigworld/src/server/tools/message_logger,
while its executable is found in bigworld/tools/server/bin. Message Logger is
a stand alone Linux process that can be run on any machine in a BigWorld
cluster that is running BWMachined.
A suite of Python tools and libraries is also provided for accessing
and manipulating logs that have been generated by Message Logger. These
tools can be found in bigworld/tools/server/message_logger.
Detailed documentation for the supported command line arguments is
available as online help using the --help option.
When a server process, such as a CellApp, is started it performs a
search of the network cluster it is operating within for all active
Message Logger processes. Any output that is generated as a result of
script print statements or C++ calls to the message
handlers (INFO_MSG, ERROR_MSG,
etc....) are sent to all known Message Logger instances. Message Logger
processes that are started after a server process will notify all running
server components of their existence and commence logging of all
subsequent messages.
The BigWorld Client can also be configured to send messages to
Message Logger. By default this is enabled in the Hybrid build and
disabled in the Release build. The Consumer build logging options are
controlled by a set of #defines in
src/lib/cstdmf/config.hpp.
The following values should be defined in the Consumer build to enable the Client to send log messages to Message Logger instances:
#define FORCE_ENABLE_MSG_LOGGING 1 #define FORCE_ENABLE_DPRINTF 1 #define FORCE_ENABLE_WATCHERS 1
Messages from the client are by default sent as the
root user (i.e., with a linux UID of 0). In order to
associate logs generated from a Client with a specific user within a
network, a Windows environment variable UID can be set.
This variable should have a value corresponding with the user's Linux
account user id. For example a developer Alice with a Linux account name
of aliceb could discover her user id on Linux by
logging in to her Linux account and typing the following command:
$ id uid=3592(aliceb) gid=501(UmbrellaCorp)
Alice can then set a Windows environment variable of
UID with the value 3592. Any logs
generated by Alice running the BigWorld Client will now be associated with
her.
Except where overridden by the corresponding command line option,
Message Logger reads its configuration from the file
bigworld/tools/server/message_logger/message_logger.conf.
The configuration file is in standard Windows INI file format, and supports the following options:
| Option Name | Description |
|---|---|
| logdir | The location of the top level directory to which Message Logger will write its logs. This option can be either a relative or an absolute path. If a relative path is specified, then it is calculated relative to the location of the configuration file. |
| segment_size | Size (in bytes) at which the logger will automatically roll the current log segment for a particular user. |
| default_archive | File used by mltar.py when the
--default_archive option is used. This file is
also inserted into Message Logger's logrotate script during
installation.
|
| groups | A comma separated list of machine group names. When
specified MessageLogger will only accept log messages
originating from machines that have a matching group name listed
in the [Groups] section of
/etc/bwmachined.conf. For more details see
Production Scalability.
|
Message Logger generates log files in a binary format in order to make the best use of disk space as possible. In order to access the binary logs, two Python modules are provided:
| Python Module | Description |
|---|---|
bwlog.so |
Location: A binary Python extension compiled from Message Logger source code. |
message_log.py |
Location: Python classes that simplify and extend the functionality
exposed from |
For examples on how to use these modules, browse the source code of the command-line message logger utilities described in Command Line Utilities.
Message Logger generates logs in a two level directory structure. The top level directory contains files that are common to all users, and contains one sub directory per user. The files in the top level directory are:
| Filename | Description |
|---|---|
component_names |
List of all distinct component names (i.e., CellApp, BaseApp, etc...) that have sent messages to this logger. This is used to resolve numeric component type IDs to names, when displaying log output. |
hostnames |
Mapping from IP addresses to hostnames. This is used for resolving hostnames when displaying log output. |
strings |
List of all unique format strings that have been sent by logging components, along with parser data for interpreting arguments to each. This is used to reconstruct the log messages from format string IDs and binary argument blobs. |
version |
Log format version. This is used to prevent accidentally mixing two log formats. |
pid |
Process id of the active Message Logger process writing logs to this directory. This is used by both the tools and Message Logger to identify the process (if any) currently generating logs. |
Each user's sub directory has a file containing its UID, as well as the following files:
| Filename | Description |
|---|---|
components |
A record of each individual process instance registered with this logger. |
entries.,
args. |
A collection of log messages. The
fixed length portion of each log message (time, component ID,
etc...) is stored in the
The variable length section data corresponds
to an entry in the format string file
|
The bigworld/tools/server/message_logger
directory contains a variety of command line utilities providing the
functionality of standard UNIX shell utilities for BigWorld message
logs. Using these utilities you can operate on the binary logs using
standard UNIX shell utilities and pipelines in the same way you can with
ordinary text files.
The following tools are provided:
| Utility | Description |
|---|---|
| mlcat.py | Provides both cat and tail -f style of text log outputting. |
| mlls.py | Displays information about log segments, such as start and end times, entry counts, and sizes; for individual users or all of them. |
| mltar.py | Provides an easy way to select log segments from a user's log and archive them, as well as all the required shared files for viewing on another machine. |
| mlrm.py | Provides an easy way to clean up unwanted log segments. |
The detailed documentation for each utility is maintained as
online help, which can be accessed via the --help
option.
The following list provides some common examples of tasks you might wish to achieve using the Message Logger tools:
-
mlcat.py -f
Watches live server logs.
-
mlcat.py --around="Mon 22 Jan 2007 19:00:00" -u devuser
Views output surrounding a log entry of interest for user devuser.
-
mltar.py -zcf bwsupport.tar.gz --active-segment
Collects logs to email to support.
-
mltar.py -u <uid> -zcf bwsupport.tar.gz --active-segment
Collects logs for the Unix user whose uid is uid to email to support.
-
mlls.py -u gameuser
Displays all log segments for user gameuser, to determine the segment with entries of interest.
-
mlrm.py --days=30
Removes logs over a month old.
-
mltar.py -xf lastweek.tar.gz -o samplelogs
Extracts the archive
lastweek.tar.gzto the directorysamplelogs.Note
Since the archives are compressed tar files, you can use tar to achieve the same results if you find that easier, as illustrated below:
$ mkdir samplelogs $ tar -zxf lastweek.tar.gz -C samplelogs
-
mltar.py -xd
Extracts the latest archive back to the default logdir.
The Linux logrotate scripts are used to rotate
(stop writing an old log file and start writing to a new file), archive
(backup the old log file), and delete (log files deemed to be past an
expiry time) log files on a daily basis, which can assist in conserving
disk space. A logrotate configuration file,
/etc/logrotate.d/bw_message_logger, is set up as
part of the Server Tools installation. For more information about
logrotate, please see the
logrotate manpage:
$ man 8 logrotate
There are two issues to consider when customising the logrotate:
-
Log rotation can put a load on the logging machine.
-
If rotation is configured to occur more frequently, for example the rotation is changed to occur on hourly basis, then in this case the
rotateoption should be updated to 168 (i.e. 7 x 24) to ensure that the log files cover the same period of time.
In order to assist Message Logger coping with heavy network and disk load in production environments, Message Logger supports logging subsets of machines within a server cluster. This is achieved by assigning a Message Logger process a list of machine groups that it should accept logs from, as well as assigning every machine in the cluster to a machine group. Both Message Logger and cluster machines may be assigned to multiple machine groups. In order to enable this feature both MessageLogger and BWMachined will need to be configured correctly throughout your cluster environment.
To limit a Message Logger process to only accept logs from a set
of machine groups requires adding a comma separated list of group names
to a groups entry in the file
bigworld/tools/server/message_logger/message_logger.conf.
For example, to assign a MessageLogger process to only accept logs from
the machine groups QA_Cluster1 and
QA_Cluster2 the following entry would be placed in
message_logger.conf:
[message_logger] ... groups = QA_Cluster1, QA_Cluster2
MessageLogger needs to be restarted in order to detect these
changes, however once restarted an entry should appear in the
MessageLogger log file
/var/log/bigworld/message_logger.log similar to the
following:
2008-11-12 11:37:20: INFO: Logger::init: MessageLogger machine groups specified. Only accepting logs from: QA_Cluster1, QA_Cluster2
For details on configuring BWMachined see Configuration.
Note
Currently in order to view the logs generated when using the
machine group log separation will require either separate
installations of WebConsole, or manual searching of the files with the
mlcat.py tool on the host where MessageLogger is
running. This limitation will be addressed in a future release of
BigWorld.
Written in Python, StatLogger is a daemon process that runs in the background, polling all servers on the network at regular intervals (by default, every 2 seconds). Any computer running BWMachined will be automatically discovered, along with any BigWorld components running on that machine. StatLogger collects and logs information for every server component discovered, regardless of which user is running them.
Statistics for machines and processes are collected in 2 ways:
-
Communication with BWMachined daemons running on each computer.
-
Requests made directly to the processes via the Watcher mechanism.
Once collected, StatLogger logs this data to a MySQL database. For details on the structure of the database, see Database Structure.
The main objective of StatLogger is to collect and store data in a format that can be used by StatGrapher[4], which is the visualisation counterpart to StatLogger, and presents the data in a graphical format.
The list below describes the requirement for running StatLogger:
-
CPU
On an Athlon 2700+, monitoring 230 processes (which includes 200 CellApps) with StatLogger consumes roughly a constant 15% of available CPU time. The MySQL daemon also experienced a constant load increase of 5.5% due to the large amount of database queries being generated.
-
Disk
Due to the amount of data being collected, StatLogger can potentially consume a lot of disk space. The rate at which disk space is consumed depends on the amount of machines and server process for which statistics are collected. 4GB is recommended for a large amount of processes (around 250) and machines over a month. The disk space consumption rate of a single log gets smaller the longer a log is run, since StatLogger stores older data in lower detail than newer data.
-
Network
StatLogger's network requirements depend on the number of server machines and components present. It can potentially require a large amount of network throughput. For example, 230 processes and 9 server machines require 100Kb/s of downstream traffic, and 20kb/s of upstream traffic, while 6 processes (i.e., for a minimal server) and 9 server machines require 4kb/s of downstream and 2kb/s of upstream traffic.
-
RAM
Memory requirements are low, as statistics are immediately logged to the database, rather than being kept in memory. Tests indicate an average usage of memory between 7MB to 10MB, regardless of the amount of processes running.
-
Software
MySQL 4.1+ and Python 2.4 with MySQLdb.
StatLogger must be run on the same local network as the BigWorld server processes that it is intended to monitor due to the manner in which machine and server component discovery occurs.
StatLogger requires a valid MySQL user with access to create databases. Normally the creation and configuration of this MySQL user is handled during the tools installation process[5], but an existing database user can be can used instead, by manually editing the configuration file. For details, see Configuration.
StatLogger outputs various status messages describing which machines and processes it discovers or loses (i.e., from the process or machine shutting down) from the network, each prefixed with a timestamp.
When running StatLogger manually from the command line the default
is to display this information to the terminal on which it is run unless
the -o option is specified.
When installed as a daemon, these messages output to the log file
/var/log/bigworld/stat_logger.log by default. This
log file is specified by the LOG_FILE variable in
/etc/init.d/bw_stat_logger.
As Stat Logger is responsible for collecting a constant stream of data from an arbitrarily large BigWorld server cluster for historical tracking it is necessary to prevent the database size from growing out of proportion. In order to achieve this Stat Logger implements a mechanism of aggregating and merging data from high resolution time periods into lower resolution time scales the older the data becomes. This approach allows high resolution data to be maintained for recent events when diagnostics are most likely to occur but allows a broad view of server performance over a long scale to be maintained. More information on customising how StatLogger aggregates data can be found below in Aggregation Window Configuration.
Located in StatLogger's directory, the preference file
preferences.xml is used to configure the script.
The preference file can be used to configure:
-
Database connection details.
-
Watcher values to collect from processes.
-
Aggregation preferences.
Apart from the database user configuration, in most cases the provided standard settings should be sufficient for development and production environments.
The preferences.xml file configures database setup options, as well as what data StatLogger should collect from the server components and machines.
The <options> section of the preferences file contains the following tags:
| Option Name | Description |
|---|---|
| dbHost | Hostname or IP address of the MySQL database server that will contain the log databases. |
| dbUser | Database user with which StatLogger (and StatGrapher) will access the database. For details on StatGrapher, see StatGrapher. |
| dbPass | Database user's password. |
| dbPort | Port on which the MySQL server is listening for connections. |
| dbPrefix | Prefix of database names which StatLogger can accesses. |
| sampleTickInterval | Interval in seconds at which StatLogger will poll the components and store statistics (decimals are supported). Generally this value does not need to be changed, however if it does, then it should not be any smaller than 2 seconds (the default recommended value). |
The <collect/aggregation/window> section configures the aggregation windows that will be stored in the database.
As outlined in Data Collection and Aggregation, StatLogger has been designed to stores multiple versions of data at varying levels of detail with the idea is that long term data does not need to be stored at the same level of detail as the more recent data.
StatLogger requires at least one aggregation window setting in this section with a samplePeriodTicks value of 1.
Multiple aggregation window setting takes the form of:
<preferences>
...
<collect>
<aggregation>
*<window>
<samples> <num_samples_in_this_win> </samples>
<samplePeriodTicks> <num_of_ticks_per_sec> </samplePeriodTicks>
</window>
...Multiple aggregation window settings (Grammar)
There are some constraints that must be adhered to when creating this list of aggregation window settings:
-
There must always be an aggregation window with samplePeriodTicks value of 1.
-
Aggregation window settings must be ordered in ascending order by their samplePeriodTicks value, with the smallest values first.
-
Each successive aggregation window should cover a larger range of ticks than the previous one. The tick range is calculated by multiplying samples value by the samplePeriodTicks value (i.e., number of samples x ticks consolidated into one sample).
-
Each successive samplePeriodTicks value must be a multiple of the samplePeriodTicks value from the previous window.
These aggregation windows are used directly by StatGrapher, so it is advised not to have large discrepancies between the samplePeriodTick values of successive aggregation windows. Furthermore, the final aggregation window setting should not have a large samples value, as this may place a heavy load on both StatLogger and StatGrapher.
An example aggregation section is shown below, with a samples value of 365:
<preferences>
...
<collect>
<aggregation>
<!-- Every sample (2secs) in most recent 24hrs. 43200 samples -->
<window>
<samples> 43200 </samples>
<samplePeriodTicks> 1 </samplePeriodTicks>
</window>
<!-- Every 10th sample (20secs) in most recent 48hrs. 8760samples -->
<window>
<samples> 8760 </samples>
<samplePeriodTicks> 10 </samplePeriodTicks>
</window>
<!-- Every 150th sample (5mins) in most recent 30 days. 8760 samples -->
<window>
<samples> 8760 </samples>
<samplePeriodTicks> 150 </samplePeriodTicks>
</window>
<!-- Every 1800th sample (60mins) in most recent 365 days. 8760 samples -->
<window>
<samples> 8760 </samples>
<samplePeriodTicks> 1800 </samplePeriodTicks>
</window>
<!-- Every 43200th sample (1day) in most recent 365 days. 365 samples -->
<window>
<samples> 365 </samples>
<samplePeriodTicks> 43200 </samplePeriodTicks>
</window>
</aggregation>
...Multiple aggregation window settings (Example)
The <collect/machineStatisticList>
section is similar to the statisticList[6] and allProcessStatisticList[7] sections, except in that watcher values are not
supported since machines do not have a Watcher interface. The
<valueAt> settings only support strings
representing members of the Machine class
defined in
bigworld/tools/server/pycommon/machine.py.
The <collect/allProcessStatisticList> section is similar to the statisticList[8] section, except that its statistics are regarded as common to all processes being monitored i.e., those specified in the <processList>[9] section.
It is recommended that any watcher values used in this section are supported by all processes being monitored, although StatLogger will store empty values for processes that do not support a watcher value.
The <collect/processList/process> section configures the statistics that will be collected for each process. There must be one process section for each server component to be monitored.
The process section contains the following tags:
| Tag Name | Description |
|---|---|
| name | Display name for the process type. |
| matchtext | Name of the component type's executable. Value must be in lowercase, like the executable names. |
| statisticList | List of statistics to be collected for this process by StatLogger[a]. |
|
[a] For details see Process Statistic Configuration. |
|
An example process section is shown below:
<preferences>
...
<collect>
...
<processList>
<process>
<name> CellApp </name>
<matchtext> cellapp </name>
<statisticList>
...
</statisticList>
</process>
...Example process configuration
The <collect/processList/process/statisticList/statistic> section specifies the statistics that must be collected for each process.
The statistic section contains the following tags:
| Tag Name | Description |
|---|---|
| name | Display name for the statistic type. |
| valueAt | Where to retrieve the values from. There are two distinct sources of information, depending on the first character of this tag's value, see the section valueAt Properties for details. |
| maxAt | This value is not explicitly used in StatLogger, however it is used by StatGrapher to determine the scale of the graph. |
| type | Current unused. |
| consolidate |
Consolidation function to use when moving data up an aggregation window. Possible values are: MAX, MIN, and AVG. Example: We consolidate four data samples at 4 seconds per sample into the next aggregation window, which stores data at 16 seconds per sample. The data represents CPU load consumed by a process. The consolidate value is specified as AVG, so StatLogger averages the four data samples, then store this value as a single value in the higher aggregation window. |
| display | Contains properties that influence the StatGrapher display of this statistics. |
An example statisticList section is shown below:
<preferences>
...
<collect>
...
<processList>
<process>
<name> CellApp </name>
<matchtext> cellapp </name>
<statisticList>
<statistic>
<name> Cell Load </name>
<valueAt> /load </valueAt>
<maxAt> 1.0 </maxAt>
<logicalMax> None </logicalMax>
<type> FLOAT </type>
<consolidate> AVG </consolidate>
<display>
<colour> #FF6600 </colour>
<show> true </show>
<description>
The load of this CellApp.
</description>
</display>
</statistic>
<statistic>
<name> Num Entities Ever </name>
<valueAt> /stats/totalEntitiesEver </valueAt>
<maxAt> 10000.0 </maxAt>
<type> FLOAT </type>
<consolidate> MAX </consolidate>
<display>
<colour> #663366 </colour>
<show> false </show>
<description>
The number of entities created on the CellApp since server startup.
</description>
</display>
</statistic>
...Process statistic configuration — Example
The behaviour of the valueAt tag changes based on the first character of the string. If first character is a slash '/' valueAt will be interpreted as a watcher path. The best way to list the watchers that can be graphed is via the WebConsole's ClusterControl module[10].
Any single scalar value present in ClusterControl can be added to StatGrapher, including any customer watcher values added within your own game code.
If the first character is not a slash, the
valueAt string is treated as referring to a
member a Process class instance as found in
bigworld/tools/server/pycommon/process.py.
Strictly speaking, valueAt is
eval'ed against the
Process object which enables slightly more
flexibility than just being able to reference class members.
Examples:
| valueAt | Interpretation |
|---|---|
| /stats/numInAoI | Watcher path of <process
type>:/stats/numInAoI |
| mem | Evaluated to
Process.mem, which
retrieves the value of memory usage of a process.
|
Note
Caution is required with this type of value as it is possible to use a function call that changes the state of the process (e.g., causing a process to shutdown). It is highly unlikely that this will occur by accident, unless the exact function call is entered in the valueAt setting.
The configuration file directly affects the database structure used for storing the statistics. If the collect section of the configuration file is changed, then StatLogger will detect the change when it is next run, and will subsequently create a new statistics database from scratch, in order to accommodate the new structure.
StatLogger uses two active databases during its operation, however over an installation's life multiple databases may be created as StatLogger options are modified.
The two active databases required by StatLogger are:
-
Statistics database associated with a unique preference configuration.
-
Meta database for tracking all statistic databases known by StatLogger.
By default, the meta database is named bw_stat_log_info and contains a single table called bw_stat_log_databases. The bw_stat_log_databases table stores the names of all the known statistics databases. The meta database is always created if it does not exist in the MySQL server.
The statistics databases by default are named
bw_stat_log_data<n>,
where <n> is the
incremental database number. Users can choose to create statistics
databases with specific names using the -n option when
running StatLogger.
New statistics databases are created in the following situations:
-
There are no statistics databases in the MySQL server.
-
The preferences file was structurally changed, which causes a new statistic database to be created. For details on the
preferences.xmlfile, see Configuration. -
StatLogger was started with the
-ncommand-line option, and there was no statistic database with that name in the MySQL server.<database_name>
There is typically no need to create new statistics databases unless isolated sets of statistics are needed. This may occur when performing tests with the BigWorld server. Once StatLogger has been configured to suit your environment only one statistics database should be needed.
Below is an overview of the tables in a statistics database. This is intended as a quick reference for locating data within the database. For a comprehensive understanding of how the data is used the source code is considered to be the best reference.
| Table Name | Description |
|---|---|
| pref_processes |
Process preferences as specified in the configuration file's <collect/processList> section. For details, see Process Configuration. |
| pref_statistics | Statistic preferences specified in configuration file. |
| seen_machines | Machines observed while StatLogger was running. |
| seen_processes | Processes observed while StatLogger was running. |
| seen_users | Users observed while StatLogger was running. |
stat_<proc>_lvl_<lvl> |
Statistics collected for processes of type
<proc>,
with <lvl>
index of aggregation.
|
stat_machines_level_<lvl> |
Statistics collected for machines with
<lvl>
index of aggregation. The higher the aggregation level, the
lower the resolution of the data being stored in that
table.
|
| std_aggregation_windows | Aggregation level details specified in configuration file's collect/aggregation section. |
| std_info |
sampleTickInterval specified in the configuration file's <options> section. For details, see Database Connection Details. Database structure version (Used internally by StatLogger). |
| std_session_times | Start and end times of when StatLogger was run. |
| std_tick_times | Timestamps of the start of each interval. |
| std_touch_time |
The last time the database was written to, in database local time. This value is only used by StatGrapher regardless of whether StatLogger is currently logging to this database or not. |
Location:
bigworld/tools/server/control_cluster.py
Control Cluster is a command line tool for managing a BigWorld cluster from a text only interface.
For detailed information on all the available commands, please
refer to the Control Cluster help by using the --help
option.
$ ./control_cluster.py --help
For detailed help information on a specific command simply provide
the command name after the --help option. For
example:
$ ./control_cluster.py --help getmany getmany <processes> [watcher-path] Queries the specified watcher path on all processes of the specified type currently active in the cluster. The path can contain '*' wildcards.
Control Cluster provides functionality through a number of commands that can be used to interact within a BigWorld server environment. The commands can be discussed in terms of four functional areas.
- Server Commands
-
Commands that operate on an entire server configuration to either modify or report its current state. This includes starting and stopping a server, saving the current server layout for reuse and displaying the current server configuration on the command line.
As server commands require interacting with a specific server instance, there is an implied user for performing these commands. Unless otherwise specified the user is taken as the username of the person running the Control Cluster command. The user to perform a command as can be changed if required by using the option
--user. For example:$ ./control_cluster.py --user bob start
- Process Commands
-
These commands operation on specific server process instances. They are used for starting and stopping server processes when there is already an active server, as well as interacting with an active server process, for example retrieving watcher values.
As with the server commands, the process commands have an implied user as they operate on server processes that have an associated user ID at runtime. The user you run a command as can be modified at any stage by using the
--useroption. - Profiling Commands
-
Profiling commands are used for diagnosing problems on server processes. While technically operating in the same way that process commands do, they are separated into a unique category to highlight their availability and encourage their usage.
Profiling commands can be used for extracting all manner of performance information from server processes including C++ performance, Python game script performance, client traffic performance and intra-process network statistics.
- Cluster Commands
-
The cluster commands are different to the server and process commands in that there is no implied user for them. These commands operate on the entire cluster as represented by every machine in the network that has a BWMachined instance running and is reachable through broadcasting. Operations such as querying all machines in the cluster for their current load and checking the validity of the BWMachined ring are included in these commands.
Many commands require a machine or machines to be provided to perform a command on. As commands quite often need to be performed across large sets of machines at the same time, Control Cluster provide a number of different shorthand notations which can be used anywhere a <machine> or <machines> is requested.
For example the start command requires a
machine set to operate on as seen by the help
output.
$ ./control_cluster.py help start start <machines> Start the server on the specified set of machines. To start the server on all machines, you must explicitly pass 'all' for machine selection.
The following list outlines the different machine selection approaches that can be used.
-
All machines
All machines in the network can be referred to using the syntax all.
-
Hostname
An exact hostname such as bw01, dmz-qa-10.
-
IP Address
An exact IPv4 address such as 192.168.1.34.
-
Hostname Wildcard
A hostname containing a wildcard such as dmz-qa-*. Be aware that depending on the unix shell you use (e.g., bash or zsh) you may have to quote the wildcard *.
-
BWMachined Version
BWMachined has a protocol version associated with each instance. If you are running multiple versions of BWMachined within your network (a practice discouraged by BigWorld), you can specify all hosts using a particular BWMachined version using the following syntax: version:
42where 42 in this case refers to protocol version 42. -
BWMachined Groups
Using the [Groups] tag in
/etc/bwmachined.confto specify different groups of machines within your server cluster, it is then possible to refer to these groups using the syntax group:groupname.
This information is also available from the command line help by
using the help command
machine-selection.
$ ./control_cluster.py help machine-selection
Similar to machine selection, many commands can operate on
numerous processes at the same time. For example the
getmany command can select watcher values from many
processes to provide a tabular report. In most cases whenever
<processes> is seen in the
help output of a command, you can use one of the
following approaches for supplying sets of processes.
The following list outlines the different process naming schemes that can be used with commands.
-
All processes
All processes in a server cluster can be referred to using the statement all. This is especially useful in relation to watcher commands.
-
Process name
An exact process name such as cellapp01 or cellappmgr.
-
All processes of a type
A set of all process types such as cellapps or baseapps.
-
Single process of a type
A process type name such as cellapp or baseapp. This can be useful when a command can be run on any process of the provided type but there may be many processes running within the server cluster.
When using this method of process selection, if there are multiple processes of the specified type running, a random process of the provided type will be selected.
-
Non-zero numbering
An exact process name that would otherwise have zero's padding the process id, such as cellapp1 or baseapp9.
The advantage of this approach is that it allows the user to take advantage of shell expansion approaches that are already available in different shells such as bash and zsh. For example in both bash and zsh using the syntax cellapp{1..3} would expand to cellapp1 cellapp2 cellapp3, while baseapp{1,7} would expand to baseapp1 baseapp7.
This information is also available from the command line help by
using the help command
process-selection.
$ ./control_cluster.py help process-selection
For details on the tools available for interacting with server message logs, see Command Line Utilities.
Note
This tool has been replaced with a web-based equivalent version, see Space Viewer. This version is now deprecated.
Location: bigworld/tools/server/space_viewer
Space Viewer is a program that is used for displaying a dynamic graphic representation of spaces. This includes the distribution of cells in a space, as well as the entities within each of the cells.
Space Viewer uses a client / server architecture, and is therefore composed of two distinct parts which may be used simultaneously or separately. The server component (SVLogger) either communicates with an active BigWorld server to collect and log information about a space, or is used to read a previously collected log. The client component (SpaceViewer) connects to the server process and uses a GUI to display the space information provided to it.
For comprehensive documentation on Space Viewer's options and
contextual help, please refer to the --help output along
with the application help available from the
menu.
Since the two halves of Space Viewer communicate via TCP, they can be run on different machines, although the client is most responsive when both components are run on the same machine.
The most common use of Space Viewer is to monitor the state of a
live BigWorld server, and as such, both the client and server components
are run in tandem. This can be achieved by simply running the SpaceViewer
script (space_viewer.py) when logged in to a GUI
session on either Windows or Linux.
Other scenarios such as during scalability testing require running
the server component as a separate process. This allows collecting space
data over long periods of time without requiring an attached GUI session.
In order to achieve this simply run the SVLogger script
(svlogger.py) from a Linux command line console. The
SpaceViewer GUI can be attached to the server process at any stage by
using the --connect option of SpaceViewer. For more
information on remote monitoring using Space Viewer, see Running Space Viewer Remotely.
The following image illustrates a number of users with active servers within the same network cluster. The dominicw user has been expanded to show all spaces that are active within that server.
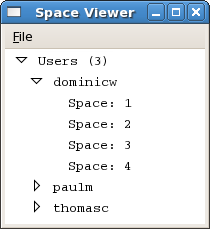
Space Viewer window
When running SpaceViewer if you do not see your username listed in the main Space Viewer window, select the File → Refresh menu item. This is sometimes required as the list is not automatically updated.
Clicking the arrow icon to the left of user name expands the list to display all spaces available for that server instance.
In the example above, the dominicw server has 4 spaces. To view the top down map of a space, double click its entry on the list. This will start an SVLogger process which will log data from the selected space as well as a new client window that attaches itself to the logger. Closing the client window will cause the logger to terminate.
Multiple spaces can be viewed simultaneously, each in their own window. To view a space, double-click its entry on the space list displayed in Space Viewer.
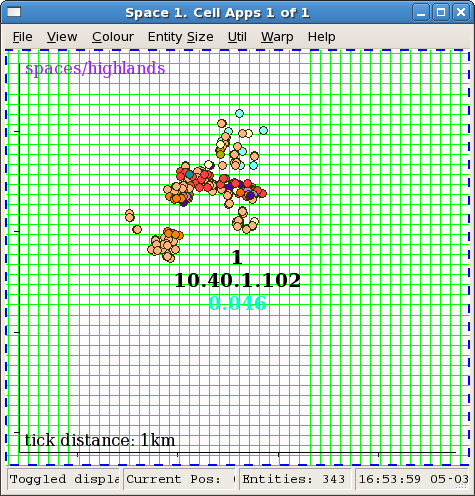
The image below shows a space being managed by five cells. Cell 2 is currently selected as can be seen by the thick blue border and coloured circles representing all the entities within the cell. Entities that are being ghosted on cell 2 are displayed as greyed out circles.
Upon first loading the space window no cell is selected for viewing. The cell boundaries and the cell information (cell number, IP address, load) will always be shown, however to see the entities within a particular cell, as with cell 2 in the screenshot below, it must be selected with a single click.
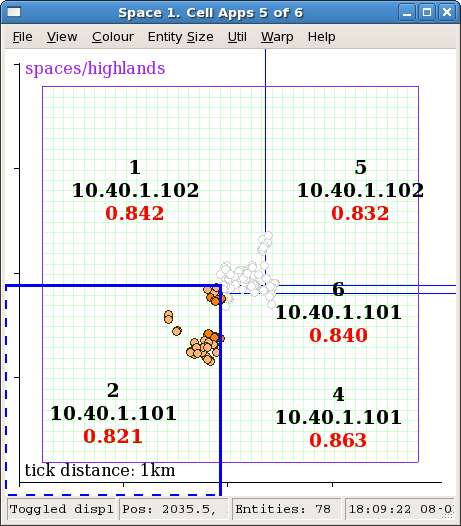
Space window
In order to facilitate identification of entities, tooltip information is available for all non-ghosted entities. This information will appear if the cursor hovers over an entity marker for a sufficiently long time.
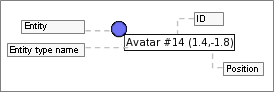
Entity tooltip
The entity type name is retrieved from file
<res>/scripts/entities.xml
Space Viewer allows you to customise the colours to be used when drawing the elements in the Space window. Any customisation is not saved and thus will not be in effect the next time the application is started. If you desire to permanently change the colours, this can be achieved by customising the Space Viewer source code.
Entities in the current cell are displayed with a coloured circle.
The colour can be customised in the file
bigworld/tools/server/space_viewer/style.py. The
simplest way to modify the colours is to update the dictionary colours
which contain RGB colour definitions for each entity type.
The code fragment below illustrates the definition of permanent entity colours:
# specify colour for specific entity types.
ENTITY_COLOURS = {
"Avatar" : ((111, 114, 247), 2.0),  "Guard" : ((244, 111, 247), 1.0),
"Guard" : ((244, 111, 247), 1.0),  "Creature": ((124, 247, 111), 1.0),
"Creature": ((124, 247, 111), 1.0),  "Merchant": ((114, 241, 244), 1.0)
"Merchant": ((114, 241, 244), 1.0)  }
}Example local file
style.py
An alternate approach would be to replace the entire function
getColourForEntity( entityID, entityTypeID ),
using your own algorithm to colour the entities.
All other colours are defined by the dictionary
colourOptions. This dictionary can be modified to any
of the colours defined by the colours array.
As described at the start of this section, Space Viewer's two components can be run separately if required. This would usually take the form of running SVLogger over an extended period of time, connecting clients to it to monitor live state as necessary, then eventually shutting down the logger. Later, SVLogger can be connected to its previously recorded log (instead of a live server) and client windows can be attached to it to replay the log data.
Location:
bigworld/tools/server/space_viewer/svlogger.py
The SVLogger script provides log writing and reading functionality for Space Viewer. In writing mode it is responsible for gathering the space data from a running BigWorld server which is achieved by polling the CellAppMgr approximately every second. In reading mode a previously recorded log is opened for replay using any client connections.
When run without any options SVLogger will default to placing
logs into /tmp/svlog-.
This location can be changed for keeping a more permanent archive of
logs by using the username-o option. For example:
$ ./svlogger -o /home/alice/space_logs
For a comprehensive list of options available for SVLogger
please refer to the command line help available from the
--help option.
Once you have started SVLogger manually, you will need to
manually connect Space Viewer client windows to the logger if you wish
to view its space data. This is easily done by running Space Viewer
with the --connect
option. For
example:
<ip:port>
$ ./space_viewer --connect 192.168.1.24:20110
The address passed to this option should be the address that SVLogger is listening for connections on, which should be displayed in the initial output from after SVLogger starts.
[4] For details, see StatGrapher.
[5] For details, see the Server Installation Guide.
[6] For details see Process Statistic Configuration.
[7] For details see Generic Process Statistic Configuration.
[8] For details see Process Statistic Configuration.
[9] For details see Process Configuration.
[10] For details see ClusterControl.