Table of Contents
BigWorld Technology's fault tolerance ensures that the server continues to operate if a single process is lost. The server also provides a second level of fault tolerance known as disaster recovery that comes into play when multiple server components fail at once and the server needs to be shut down.
For additional protection against exploits or bugs the database should be backed up regularly. The snapshot tool facilitates making backups of the database.
The server's state can be written periodically to the database. In
case the entire server fails, then it can be restarted using this
information. To enable the periodic archiving of entities, game time and/or
persistence of space data, an archive period needs to be set via the
configuration option
<archivePeriod> for BaseApp and CellAppMgr
processes. For more details, see BaseApp Configuration Options, and CellAppMgr Configuration Options.
Disaster recovery only works when the underlying database being used is MySQL, the XML database should not be used in mission critical environments. See MySQL Support for more information on how to enable MySQL database support in BigWorld.
Starting the server using recovery information from the database is the same as starting it from a controlled shutdown. For more details on controlled shutdowns see Controlled Startup and Shutdown.
For details on the scripting API related to disaster recovery, see the document Server Programming Guide's chapter Disaster Recovery.
When using Secondary Databases, it is necessary to snapshot all data sources at the same time to attempt to provide a cohesive data set that can be restored from. For background information on the need for the snapshot tool see Server Programming Guide's chapter Database Snapshot.
The snapshot tool is a Python script that facilitates making a
backup copy of the database that combines information from the primary
database and secondary databases. The script itself is located in
bigworld/tools/server/snapshot/.
When running the snapshot tool a separate machine should be used to invoke the script to avoid interfering with the normal operation of the server. The snapshot tool can use a significant amount of CPU and disk resources and does so erratically. Henceforth the machine running the snapshot tool will be referred to as the snapshot machine.
The snapshot tool performs the following sequence of operations:
-
TransferDB (
bigworld/bin/Hybrid64/commands/transfer_db) is executed on each BaseApp.TransferDB performs a snapshot of the secondary database and sends the newly created snapshot back to the snapshot machine using Rsync.
-
TransferDB is executed on the primary database's MySQL server.
TransferDB performs an LVM snapshot of the primary database and sends the newly created snapshot back to the snapshot machine using Rsync.
-
A MySQL server is started on the snapshot machine and specifies its data directory to be the copy of the primary database.
-
Data consolidation is performed on the snapshot copies of the primary and secondary databases.
-
An archive is created of the consolidated snapshot.
The snapshot tool logs all messages to MessageLogger.
Note
A snapshot should be considered invalid if an error occurs during any phase of the snapshot procedure.
The snapshot tool requires a single command-line argument
specifying the directory the snapshot will be written to, and may also
be provided options if required. Options available to the snapshot tool
are described in the --help as listed below:
Usage: snapshot.py [[options]] SNAPSHOT_DIR
Options:
-h, --help show this help message and exit
-b BWLIMIT_KBPS, --bwlimit-kbps=BWLIMIT_KBPS
file transfer bandwidth limit in kbps, default is unlimited
-n, --no-consolidate skip consolidation, default is falseThe list below provides some common examples of using the snapshot tool:
-
snapshot.py /home/bwtools/snapshots
Takes a snapshot. The snapshot is archived to
/home/bwtools/snapshots. -
snapshot.py /home/bwtools/snapshots --bwlimit-kbps=5000
Takes a snapshot. The snapshot is archived to
/home/bwtools/snapshots. Each secondary and primary database is transferred with a 5000 kbps bandwidth limit. -
snapshot.py /home/bwtools/snapshots --no-consolidate
Takes a snapshot. The unconsolidated snapshot is archived to
/home/bwtools/snapshots. -
snapshot.py /home/bwtools/snapshots -n -b5000
Takes a snapshot. The unconsolidated snapshot is archived to
/home/bwtools/snapshots. Each secondary and primary database is transferred with a 5000 kbps bandwidth limit.
For the snapshot tool to work, the following conditions must be met:
-
Secondary databases must be enabled.
To enable secondary databases set the
baseApp/secondaryDB/enableproperty to true. See Secondary Database Configuration Options for details. -
The primary database is stored on an LVM volume and there is sufficient unpartitioned space on the primary database machine to perform an LVM snapshot. Note that, for the purposes of database snapshotting, no other cluster machine is required to have spare unpartitioned space on a LVM partition. See also Partitioning.
-
BWMachined must be running on the primary database machine.
For background information see Server Overview's chapter Server Components→BWMachined.
-
All the entity scripts and entity definition files must be present and locatable on the snapshot machine.
In order for the resource tree to be found the BWMachined configuration file (
.bwmachined.conf) must be configured correctly for the user running the snapshot tool. -
The snapshot section in
/etc/bigworld.confmust be configured correctly on the primary database machine.See Configuration.
-
The directory the LVM volume is to be mounted to exists and has no other devices mounted to it.
-
The user performing the snapshot must be able to connect to the snapshot machine using ssh from the primary database machine and BaseApp machines without a password.
For a user whose
$HOMEdirectory is shared between machines (e.g, using NFS) this can be done using the following commands:$ ssh-keygen -t dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
-
The LVM userland program suite must be installed and accessible by the snapshot user on the primary database machine.
The LVM userland applications can be installed under CentOS using the command:
# yum install lvm2
By default the tools are installed into
/usr/sbin, so it might be necessary to modify the snapshot user's environment settings to at this directory to the$PATH.You can do this by adding to the PATH environment variable in the
$(HOME)/.bash_profileexport PATH=$PATH:/usr/sbin
You will need to logout and log back in for this change to take effect.
-
The following standard system applications must also be accessible by the snapshot user. mount, umount and chmod.
-
MySQL server must be installed on the snapshot machine. Specifically mysqld_multi must be accessible.
To install the MySQL server binaries, run the following command as root:
# yum install mysql-server
-
Rsync must be installed and be on the path of all machines being used, i.e, the snapshot machine, the primary database machine as well as all the BaseApp machines.
To install Rsync run the following command as root:
# yum install rsync
-
The SnapshotHelper utility must be built and installed.
If the BigWorld server was installed using an RPM package, the SnapshotHelper should already be installed under the
bin/Hybrid64/commands/_helpersdirectory of your RPM installation.If your server installation is not from an RPM you may need to recompile the SnapshotHelper. To build the SnapshotHelper binary, MySQL development files must be installed. See Compiling DBMgr with MySQL Support for details on how to install MySQL development files.
After installing MySQL development files, issue the make command from within the
bigworld/src/server/tools/snapshot_helper/directory.$ cd bigworld/src/server/tools/snapshot_helper $ make
-
The SnapshotHelper binary must have its setuid attribute set so user ID is root upon execution on the primary database machine.
To make the SnapshotHelper binary setuid root run the following commands as the root user:
# chown root:root $MF_ROOT/bigworld/tools/server/bin/Hybrid[64]/snapshot_helper # chmod 4511 $MF_ROOT/bigworld/tools/server/bin/Hybrid[64]/snapshot_helper
Note
For security purposes all privileged commands
(lvcreate, lvremove,
mount, unmount and
chmod) are invoked via
snapshot_helper which reads command arguments from
the trusted file /etc/bigworld.conf.
The snapshot tool requires that you have unallocated space on the LVM logical disk that your MySQL database resides on. As a rule-of-thumb, we recommend that the size of the unallocated space be 15-20% of the overall volume's size. Having too little space will cause the snapshot tool to fail.
Unallocated space can be added when partitioning the disks of a machine hosting MySQL. The steps below illustrate how to add a region of unallocated space for snapshotting, in addition to a swap partition and a file system partition.
-
In the disk partitioning step, choose Create custom layout.
-
Select the LVM group VolGroup00 that is created by default, and click on the Edit button.
-
Select each of the LogVol00 and LogVol01, and delete them. You may wish to take note of the size of the swap partition (LogVol01), and reuse this size when recreating the swap partition.
-
Add a new logical volume by clicking on the Add button. The mount point should be
/, and we recommend you leave the default filesystem as ext3. The size should be 80-85% of the overall size of the volume group, less the space allocated for swap. In the example illustrated in the image below, we have allocated split a 12160MB drive into 1984MB to be unallocated, 1024MB for swap, and 9152MB for the / mount which will hold the file system.
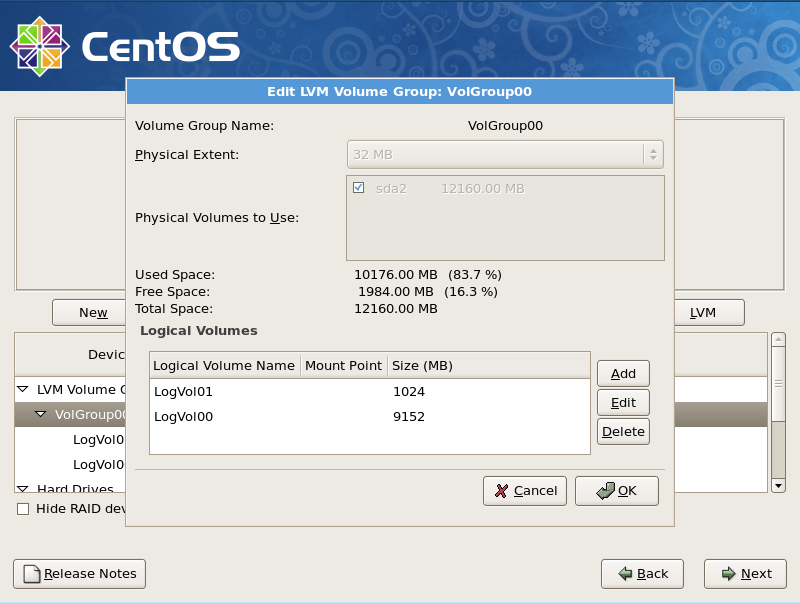
LVM partitioning setup
If you need to modify your LVM partition structure after the primary operation system installation, you may wish to use the LVM system configuration tools. These can be installed using the following command as the root user:
# yum install system-config-lvm
The snapshot tool behaviour can be be configured using the file
/etc/bigworld.conf.
Options for the snapshot tool must be placed within a [snapshot] section. Below is a list of valid keywords that can be used in the configuration file:
-
datadirThe primary database's data directory. By default for CentOS distributions this is
/var/lib/mysql.This should be the same value as found in the MySQL configuration file
/etc/my.cnf.$ cat /etc/my.cnf [mysqld] datadir=/var/lib/mysql ...
-
lvgroupThe name of the LVM volume group in which the primary database belongs to.
Note
The LVM snapshot that is created will belong to this LVM group.
-
lvoriginThe name of the origin LVM volume snapshotted. The MySQL data directory should be on this volume.
-
lvsnapshotThe name of the LVM snapshot volume that will be created and deleted by the snapshot tool.
For example, if
lvgroupis VolGroup00 andlvsnapshotis ExampleSnapshotVolume, a new volume device will be created called/dev/VolGroup00/ExampleSnapshotVolume.The snapshot name is also used to mount the snapshot volume device onto the active filesystem. Using the previous example the following mount command will be issued:
mount /dev/VolGroup00/ExampleSnapshotVolume /mnt/ExampleSnapshotVolume
Note
The mount point
/mnt/is assumed to already exist on the system prior to snapshots being created.lvsnapshot -
lvsizegbThe size of the LVM snapshot volume in gigabytes. The snapshot does not need the same amount of storage the origin has as only the modified files are copied, in a typical scenario, 15-20% might be enough. If the LVM snapshot volume becomes full it will be dropped, so it is important to allocate enough space.
Below is an example /etc/bigworld.conf
configuration file:
[snapshot] datadir = /var/lib/mysql lvgroup = VolGroup00 lvorigin = LogVol00 lvsnapshot = bwsnapshot lvsizegb = 2
Note: The snapshot tool also
reads
<res>/server/bw.xmldbMgr/host,
dbMgr/username, dbMgr/password
and dbMgr/databaseName.
The snapshot tool will take a copy of a MySQL data directory consolidated with a copy of the secondary databases. To restore from a snapshotted MySQL data directory, perform the following steps on the machine hosting MySQL:
-
Stop the BigWorld server if it is running.
-
Stop the MySQL server if it is running, you can do this by running as root:
# /etc/init.d/mysqld stop
-
Move the existing
/var/lib/mysqlto a temporary location. You may choose to remove it after the restoration process is complete. For example:# mv /var/lib/mysql /tmp/mysql-backup
-
Copy the snapshot directory's
mysqldirectory to/var/lib/mysql(you will generally need to be root to do this) Note that snapshots are identified by date and time of the snapshot, and that the colons used in the time need to be escaped by a backslash. For example:# cp -r snapshots/20100924_152642/mysql /var/lib
-
Change the ownership and permissions:
# chown -R mysql:mysql /var/lib/mysql # find /var/lib/mysql -type d | xargs chmod 700 # find /var/lib/mysql -type f | xargs chmod 660
-
Restore the SELinux contexts for these files:
# /sbin/restorecon -r /var/lib/mysql
-
Start the MySQL server, verify it is running.
# /etc/init.d/mysqld start
-
Start the BigWorld server.
The data consolidation tool is used to incorporate data from
secondary databases into the primary database. The application binary is
located in
bigworld/bin/Hybrid[64]/commands/consolidate_dbs.
This tool is only provided in source code form and must be built before
use. See Enabling Secondary Databases for details
on how to build the data consolidation tool.
Once this tool has been compiled, providing DBMgr is using MySQL the data consolidation tool will be automatically run during system shutdown or during system startup if the server was not shutdown correctly. There should be no need to manually run this tool except for consolidating backups created by the snapshot tool. For details on the snapshot tool see Database Snapshot Tool. The data consolidation tool sends log messages to MessageLogger which can be viewed using the LogViewer tool in WebConsole.
This tool accepts two command line arguments:
-
Primary Database
The parameters required to connect to the primary database.
This argument should be specified in the form
host;username;password;database_nameNote
When specifying this argument on the command line, it is necessary to quote the entire argument in order to prevent the shell from treating it as multiple commands.
For example:
./consolidate_dbs "qa_host_03;bigworld_user;bigworld_password;fantasydemo"
-
Secondary Databases
A file containing a newline separated list of fully qualified paths to secondary database files.
When run without command line arguments, it will use DBMgr's
configuration options located in
<res>/server/bw.xml
The data consolidation tool uses the transfer_db
utility located in located in bigworld/bin/Hybrid[64]/command
to transfer the secondary database files from the BaseApp machines to the
machine where the data consolidation tool is running. The
transfer_db utility will be launched (via
bwmachined) on each machine that contains a secondary
database file. The transfer_db utility then opens a TCP
connection to the data consolidation tool through which it will send the
secondary database file.
The data consolidation tool will store the secondary databases
locally in the directory specified by the
<dbMgr>/<consolidation>/<directory>
configuration option. It will incorporate the data from the secondary
databases into the primary database once all the secondary database files
have been transferred to its local machine. If the data consolidation
process is successful, both the local and remote copies of the secondary
databases will be deleted, and the
bigworldSecondaryDatabase table will be cleared. If the
data consolidation process is unsuccessful, only the local copy of
secondary database files are deleted.
The data consolidation tool logs to Message Logger under the
ConsolidateDBs process. Under most circumstances, the
data consolidation tool will log errors from
transfer_db as well. However, under some circumstances,
transfer_db errors will appear under the
Tools process. The bwmachined logs,
in /var/log/messages on each
machine where secondary databases are located, can help to diagnose
problems, especially those related to the failure to run
transfer_db.
If, for some reason, there is a problem with the data
consolidation tool and the server refuses to start, the
bigworldSecondaryDatabase table can be manually
cleared to skip the data consolidation process. Alternatively,
consolidate_dbs can be run with the command-line
parameter --clear to achieve the same result.
While skipping the data consolidation process may allow the server to start again, the data in the secondary databases that were not consolidated is essentially lost. Though the secondary database files still exists, it is not recommended to try to consolidate the data after the server has been restarted since the data in the primary database may be more recent than the data in the left over secondary databases.
When consolidate_dbs encounters an error in
reading a secondary database file, it will abort the entire data
consolidation process. Such errors should be investigated and corrected.
If a secondary database file is genuinely corrupted and cannot be
repaired, then it may be preferable for
consolidate_dbs to read as much data as possible from
the corrupted secondary database and then proceed to consolidate the
rest of the secondary databases. When the
--ignore-sqlite-errors command-line option is
specified, consolidate_dbs will proceed to
consolidating the next secondary database when it encounters an error
instead of aborting the consolidation process.